
It is important to always strive for the best time complexity when solving algorithm problems. I recently solved for the brute force solution to this problem and was ready to move on. Then, a fellow programmer on the world-wide-web reached out to me and encouraged me to do better! He showed me a solution that was much better than mine. The only problem was that I didn’t understand it at all. Well, now I do understand it. AND I want you to understand it too!
The Problem
A happy string is a string that:
- consists only of letters of the set [‘a’, ‘b’, ‘c’].
- s[i] != s[i + 1] for all values of i from 1 to s.length – 1 (string is 1-indexed).
For example, strings “abc”, “ac”, “b” and “abcbabcbcb” are all happy strings and strings “aa”, “baa” and “ababbc” are not happy strings.
Given two integers n and k, consider a list of all happy strings of length n sorted in lexicographical order.
Return the kth string of this list or return an empty string if there are less than k happy strings of length n.
Example
We will be using example 3. To see more examples, check out the problem on LeetCode. Also read about Lexicographical Order.
Example 3:
Input: n = 3, k = 9
Output: “cab”
Explanation: There are 12 different happy string of length 3 [“aba”, “abc”, “aca”, “acb”, “bab”, “bac”, “bca”, “bcb”, “cab”, “cac”, “cba”, “cbc”]. You will find the 9th string = “cab”.
Brute Force
First, I should mention that the purpose of this post is to compare the efficiency of the different solutions and then to really dive into the most optimal solution.
If you are just starting out with backtracking and recursion, check out these three great problems to get started:
This brute force solution uses recursion to create all of the happy strings from letters ‘a’, ‘b’, and ‘c’ and store them in a list. Notice that when “dfs” is called, the for loop that iterates through “abc” starts at the first possible letter, ‘a’. This is what allows repeat letters to appear in the happy strings. Also note that the happy strings will be generated in lexicographical order.
That is a lot of extra work though! As you can see up in example 3, twelve strings were created and stored in a list. We are only interested in one string, so there is probably some room for improvement.
Also, here is a way to calculate the number of total happy strings from n.
Time Complexity
The first character in one of our happy strings can be three possible different letters. The rest of the letters in the string (n-1) though can only be two possible letters. The total number of permutations is 3 * 2^(n-1). Three options for the first letter, two options for the rest of the letters. 3 is a constant and is dropped. The time complexity is O(2^(n-1)).
Space Complexity
The space complexity is O(n) for the height of the recursion stack and O(3*2^(n-1)) for the strings stored in the list. This gives O(n + 3*2^(n-1)). This is asymptotically equivalent to O(2^(n-1)).
Learn more about Big-O.
A Bit Less Brute
This approach uses backtracking and is certainly more efficient than the last approach. For each “backtrack” call there is a parameter “remain” This keeps track of the length of “sb”. When “remain” is 0, there is a global counter that is incremented. Each “sb” is generated in lexicographical order, so when count = k, we know that the current string is the k-th string.
What is nice about this approach is that all of the the possible happy strings aren’t generated. Only up until the k-th string are generated. Also, none of them are stored in a list. This saves time and space.
Time Complexity
We evaluate k strings of n length. The time complexity is O(k * n).
Space Complexity
The space complexity is O(n) for the recursion stack.
Optimal Solution
When I first solved this problem, I was only able to come up with the brute force solution. I then saw the second solution on the discussion board and saw how it was a nice optimization to the brute force solution. Keeping a global counter and getting rid of the storage list are two really good improvements.
I had also seen another solution. This solution was able to do it in linear time. The only problem was that I could not understand the solution at all. I took a glance at it, scratched my head, and put it in my “come-back-to” list. Here is the post that has the solution that I am talking about.
Not to get too far off topic, but I want to mention that I have been doing the #100DaysOfCode Challenge. One day I posted about solving the brute force solution. A week or two later someone who had read my post, emailed me some Python code that was very similar to the Java solution that I had put in my “come-back-to” list. His code could do linear time as well.
The code I posted for the #100DaysOfCode challenge only did O(2^(n-1)). I decided that I needed to do better!
First let’s take a look at the code that was generously donated by Sahand. We won’t spend time going into it, but the logic used is very similar to the Java linear time solution that we will be going over.
Thanks again Sahand!
Now let’s take a look at the Java solution that I will do my best to explain.
This solution was posted by LeetCode user @vortrubac. Here is the original post again.
Let’s go through this code line by line. Remember how I mentioned that the first letter in the string can be three possible characters and then the rest of the letters (n-1) can be two possible characters? Well, that is what is going on in lines 3-4.
Line 3 is just a fancy way of writing this: Math.pow(2, (n-1)). Using the left shift operator is just another way to do it. But, really what you are doing is taking 1 and shifting the bits left n-1 places and filling 0’s in the void. So for n = 3, prem = 1 0 0 = 4.
“prem” also corresponds to the total number of happy strings. Well, sort of. You have to multiply “prem” by 3 to get the total number of happy strings. 3 represents the first letter. Lines 4-5 are making sure that the k-th value does not exceed the total number of happy strings.
While on the topic of bitwise operators, in line 10 that is a signed right shift. It does the opposite of left shift. It basically divides a number by two. Read more about bitwise operators. Check out this great video too.
Also, here are two problems that I think are good bit problems:
Ok, now that we have the bit stuff out of the way, let’s move on to the tricky parts. When I was first trying to figure out this solution, I worked through lines 6-14 and sure enough it worked. The StringBuilder creates “cab” which is the 9th lexicographically-sorted happy string. However, I could not figure out why it worked.
Someone in the comments mentioned that this problem follows a similar method. Something about using the Factorial Number System. Still couldn’t figure it out.
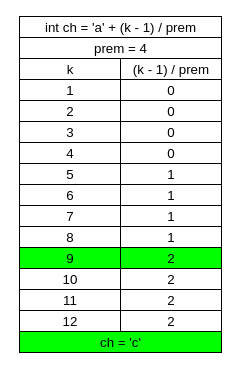
We know that line 6 is used to find the first character in the k-th happy string. In line 6 “ch” is starting with a base ‘a’. We know that the first letter in our happy string can be either ‘a’, ‘b’, or ‘c’. That means that (k-1)/prem has to equal either 0, 1, or 2. This creates three groups. In group 1, four strings start with ‘a’. In group 2, four strings start with ‘b’. In group 3, four strings start with ‘c’.
k = 9, so (9-1)/4 = 2. ch = 099, (char)ch = ‘c’. Check this ASCII Table to be sure.
But how do we decide whether (k-1)/prem is 0, 1, or 2? Check the list in example 3. Happy strings 1-4 start with ‘a’. Happy strings 5-8 start with ‘b’. Happy strings 9-12 start with ‘c’.
Ok now I know this is going to sound ridiculous, but this is the part that really hung me up: Why do we subtract 1 from k? I came this close to calling it quits on this post, because I could not find a proper way to explain why 1 was being subtracted from k.
Then I got it! I put together some tables that I think will allow you to get it too. In Table 1, you can see our three groups.
And Table 2 shows why 1 is subtracted from k.
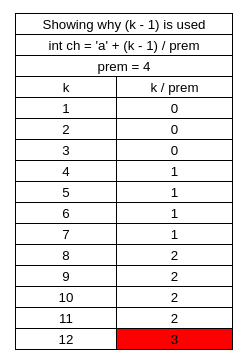
k-1 is just a nice trick that allow there to be an equal distribution of 0, 1, and 2. It also guarantees that there isn’t a 3. 3 would mean ‘d’ and ‘d’ makes our strings unhappy.
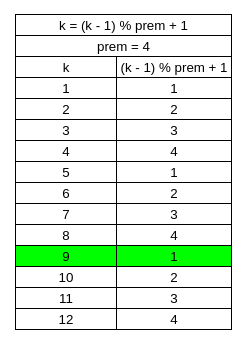
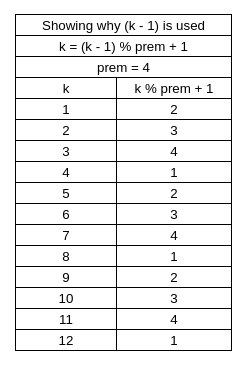
As you can see in Table 3, k can possibly be 1-12, but (k-1) % prem + 1 will reassign k so that it can instead only be 1-4. Go look at the list for example 3. Look at the second letters for each happy string.
Let’s take the happy strings that have a first letter of ‘c’ for example. “cab”, “cac”, “cba”, “cbc”. The second letter is ‘a’ for the first two happy strings and then ‘b’ for the last two happy strings. This is where our new values of k come in handy. After we reduce “prem” by an order of 2, it is quite handy to divide (k-1) by “prem”.

Now look! Because “prem” was reduced by a factor of two, (k-1)/prem at the beginning of the ternary operator can only either be 0 or 1 as seen in Table 5. If it is 0 then the conditional is truthy and “ch” will either be ‘a’ or ‘b’ depending on what “ch” currently is. If (k-1)/prem is 1 then the conditional is falsy and “ch” will either be ‘b’ or ‘c’ depending on what “ch” currently is.
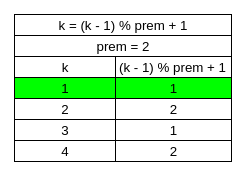
Now back to line 9 for Table 6. k ranges from 1-4 and (k-1) % prem + 1 will “index” the k values like it did in Table 3.

Table 7 shows that prem = 1 which means that the while loop will terminate after the last “ch” is appended to “sb”.
result = "cab"
Time Complexity
The time complexity for this algorithm is O(n). There is one string of size n that is built.
Space Complexity
The space complexity for this algorithm is O(1).
Get Better at Algorithms!
Algorithms and data structures are pretty tough. They are definitely taking a while for me to get the hang of them. However, there are some great resources out there, and I feel obligated to share some that have been most helpful to me. If I missed any that have been helpful to you, be sure to mention them in the comments.
- Cracking the Coding Interview – Great resource. Really gets you in the right mindset for interviews. You can find it here.
- Elements of Programming Interviews – Another great book. Personally, I like this one more than CTCI, but YMMV. You can find it here.
- Grokking the Coding Interview – Can’t emphasize this one enough. Haven’t seen it mentioned it too often. Explains patterns that occur in different coding challenge problems. Great at providing a big-picture of all the different algorithm problems you might encounter. Check it out here.
- Grokking Dynamic Programming – Dynamic programming is tough. This course has definitely helped me get a better understanding.
- Tushar Roy – Tushar really knows his stuff. His dynamic programming playlist is especially good. Check out his awesome YouTube channel.
- Back To Back SWE – Great YouTube Channel. Highly recommend.
- Kevin Naughton Jr. – Another awesome YouTube channel. Great at going over problems and gives helpful advice.
- Base CS – Vaidehi Joshi does a great job of laying out the fundamentals of algorithms and data structures. Check out the blog series here. She also has a podcast that I give two thumbs up.
- Coding Challenge Website – There are plenty of different ones to choose from. HackerRank, CodeWars, and Edabit all seem to be pretty popular. I personally use LeetCode. Find the one that works for you!
- Pramp – Do mock interviews! The sooner the better! Pramp has been a huge help to me. Pramp does free peer mock interviews. Doing peer mock interviews has its drawbacks, but it’s free! If it’s free, then it’s for me!
- Interviewing.io – Will cost some money, but it is worth it. Get excellent practice by doing mock interviews with actual software engineers. Check out Interviewing.io.
Well, I hope that was useful. Thanks for reading my post and best of luck with your learning about data structures and algorithms!
Dedication
This post is dedicated to Sahand. I wouldn’t have taken the time to figure out the optimal solution, if you didn’t send me that Python code, so thanks!