
As I am continuing to learn more about algorithms and data structures, I have found one particular kind of problem that has been giving me trouble: Breadth First Search. Because I was having a hard time grasping this concept, I figured that the best thing for me to do would be to blog about it. So, time to put our differences aside, BFS, because by the time this is over, you and I will be BFFs.
What is this blog post about?
I understand what BFS is on a high level. That is not the problem. The problem is being able to use BFS when solving coding challenge problems. This blog post is going to go over a coding challenge problem that uses BFS. The problem will focus on the level order traversal of a binary tree and break down the problem step-by-step.
However, if you are completely new to BFS, then fear not! Vaidehi Joshi has written a wonderful blog post about BFS. In fact, you might as well check out another post of hers where she has written about Depth First Search (DFS) as well. IN FACT, check out all of her work from her Base CS blog series. I can’t emphasize just how much she has helped me learn about algorithms and data structures. Thanks Vaidehi!
Binary Tree Level Order Traversal
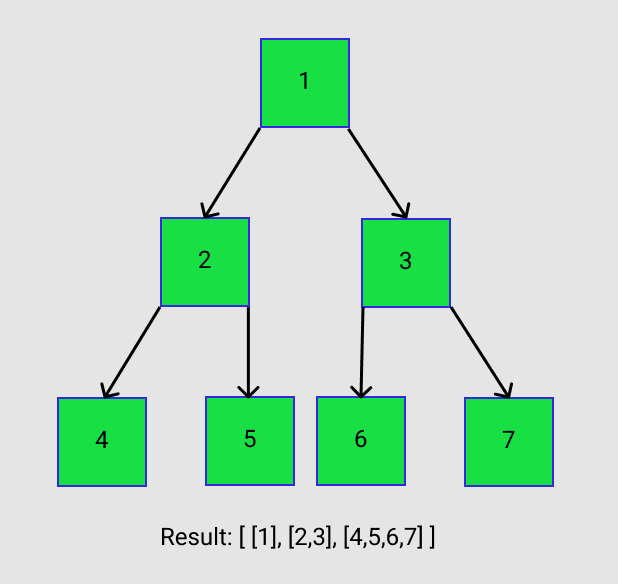
Problem: Given a binary tree, populate an array to represent its level-by-level traversal. You should populate the values of all nodes of each level from left to right in separate sub-arrays.
This problem like most BFS problems will use a queue to perform its search. On the other end of the spectrum, DFS alogrithms typically utilize a stack along with recursion to perform its search. If you are rusty on stacks and queues then use this useful resource to get up to speed. Similarly, if you are rusty on trees then use this other useful resource to get up to speed.
The desired result of the problem seems simple enough to obtain. It is just a nested array with each sub-array representing a different level of the tree. The elements of the sub-arrays contain the values of each of the nodes for each level.
But how do we get to the result? We use a queue. Vaidehi discusses in her BFS post that even though the nodes across a level are not connected, we can still push all of the tree nodes for a level onto the queue and then add the values for those elements to a sub-array which will then get added to the main array.
The Code
Let’s take a look at the code to solve this problem. Read through the code and make as much sense of it as possible. Then we can go through it step-by-step and make sure that we understand it completely.
Here are the steps that the algorithm takes:
- Push the root node onto the queue.
- Iterate until the queue is empty. This will be when there are no more tree nodes left.
- At each iteration, the number of elements in the queue needs to be counted. This will allow the sub-array for that level to be set to the correct length and also allow for the correct number of iterations.
- Then remove the nodes for that level from the queue and add their values to the sub-array.
- As the nodes are being removed from the queue insert each of their children nodes into the queue.
- Keep doing this until the queue is empty.
Some Illustrations
I know what might be helpful! How about we use some illustrations to help us better understand what is going on in the algorithm.
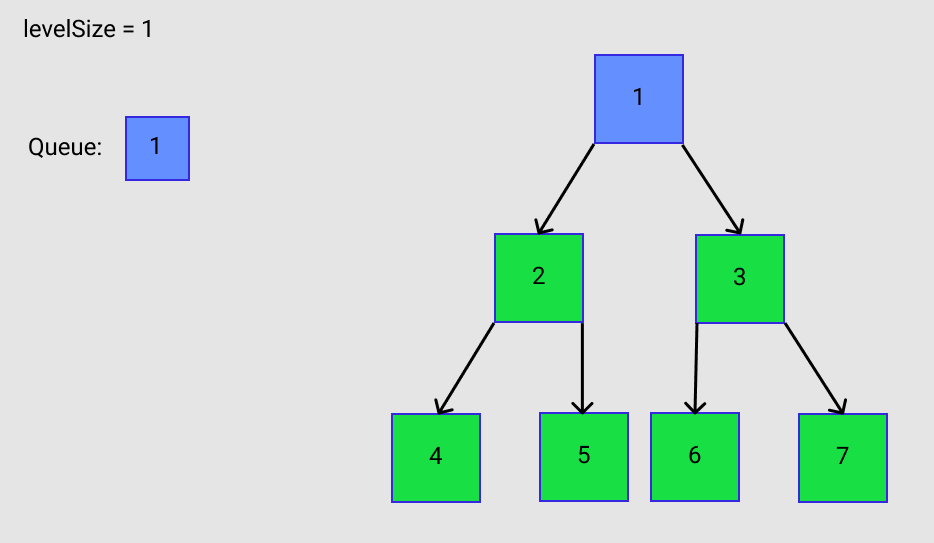
Take a look at Figure A. The root node gets pushed onto the queue. This happens on line 20 of the code. If you are not familiar with the Java implementation for a queue then check out the docs. Also in line 22 a variable levelSize is created that keeps track of the number of nodes in the queue.
The next step is to move the number of nodes that is equal to levelSize out of the queue (line 25). Currently levelSize = 1. So the node that has a value of 1 is removed from the queue and added to a sub-array (line 27). But as that node is leaving, IF it has any children they will get added to the queue (lines 29-32). This is illustrated in Figure B. Finally, the sub-array gets added to the result list (line 34).
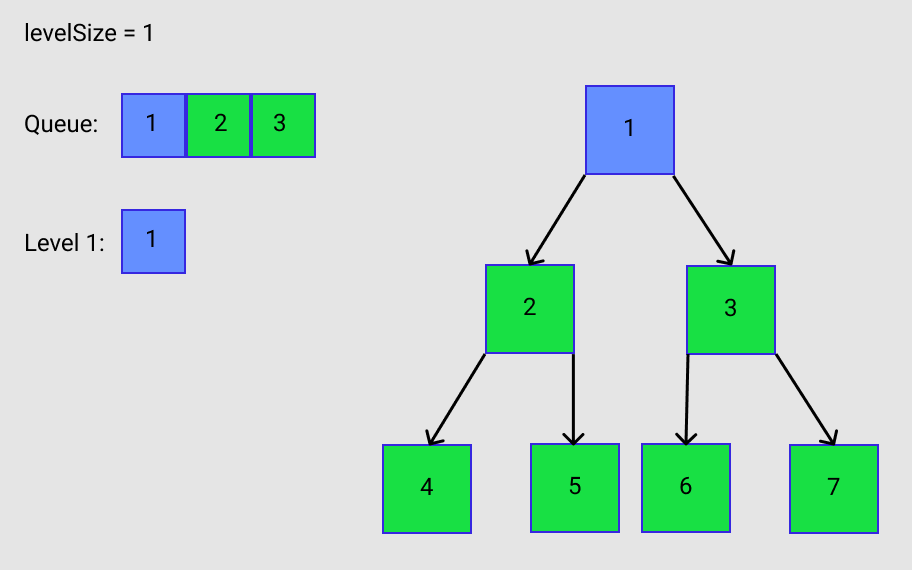
The node with a value of 1 is no longer part of the queue. Now its children are the only nodes in the queue. These elements are now counted. Notice in Figure C how levelSize now equals 2.
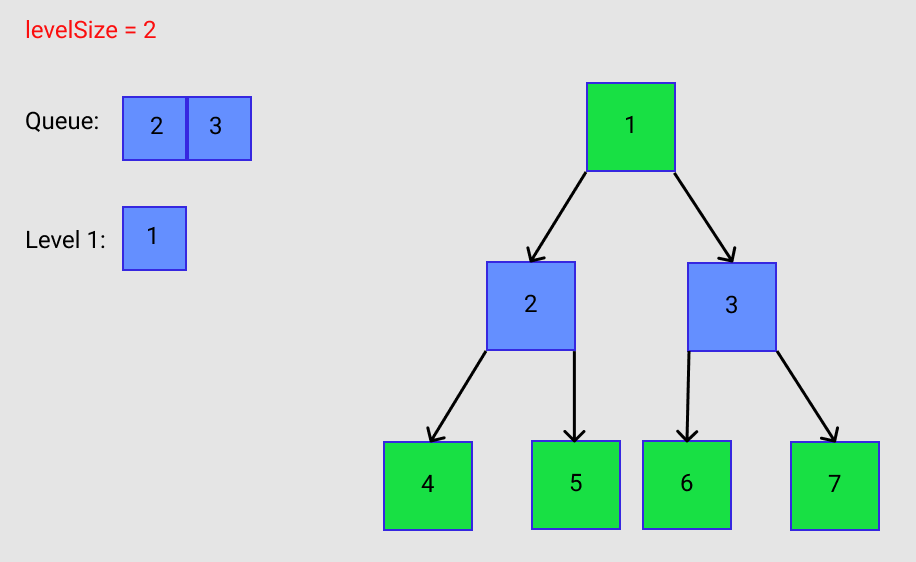
Now with a levelSize = 2 the for loop on line 24 allows us to iterate through the two elements of the queue. It should also be noted that a sub-array that is the length of levelSize is created on line 23. The node that contains the value 2 and the node that contains the value 3 are removed from the queue and added to the result list. BUT, as they are leaving, 2’s children and 3’s children are being added to the queue. This is shown in Figure D.
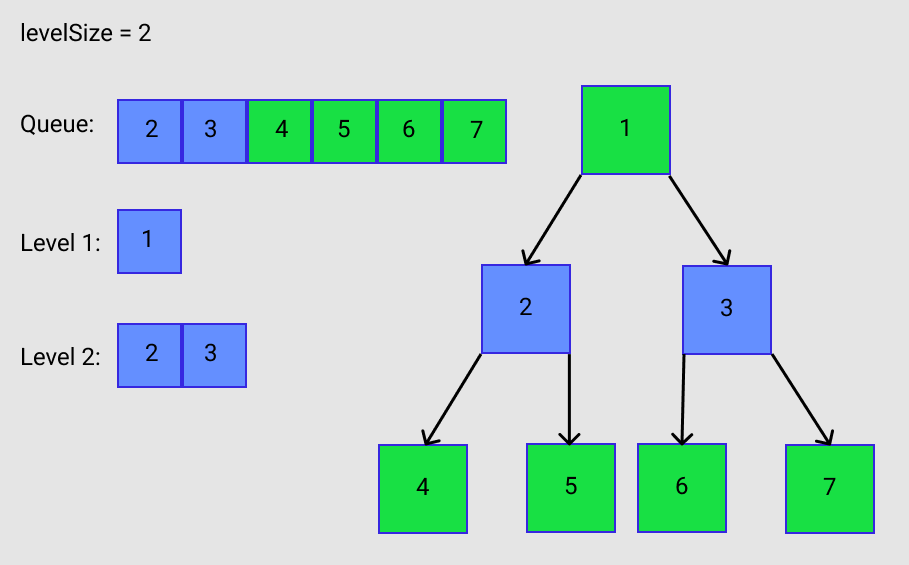
Nodes 2 and 3 are no longer in the queue. Nodes 4, 5, 6, and 7 are in the queue. They are counted and levelSize = 4. This is shown in Figure E. Remember lines 29-32? These nodes have no children. They are going to be removed from the queue, but because they have no children, no additional nodes will be added to the queue.
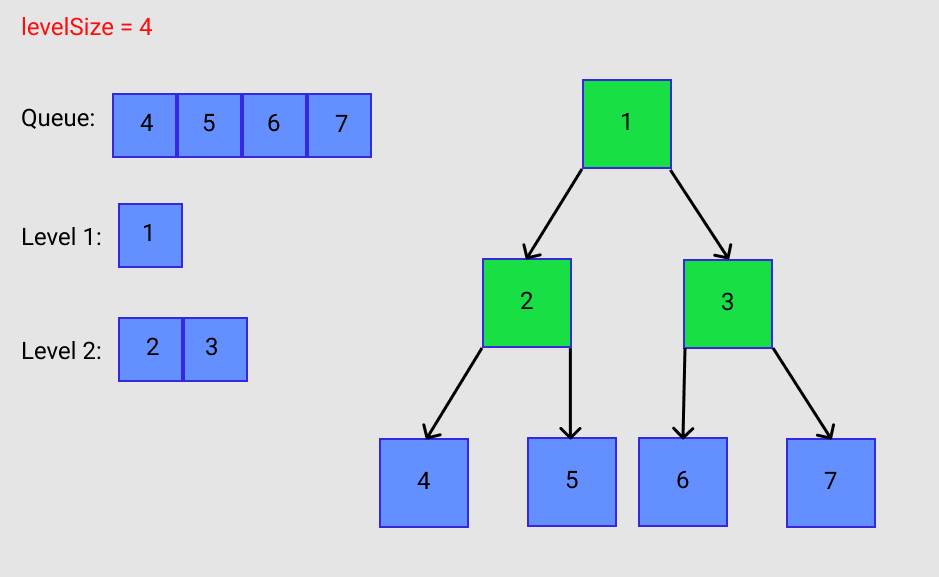
I want to mention again that no nodes were added to the queue as nodes 4, 5, 6, and 7 were being removed and added to the result list. The queue is now empty. This terminates the while loop on line 21. Look at Figure F. We now have a traversed tree, an empty queue, and a filled list with the results that we wanted. Neat!
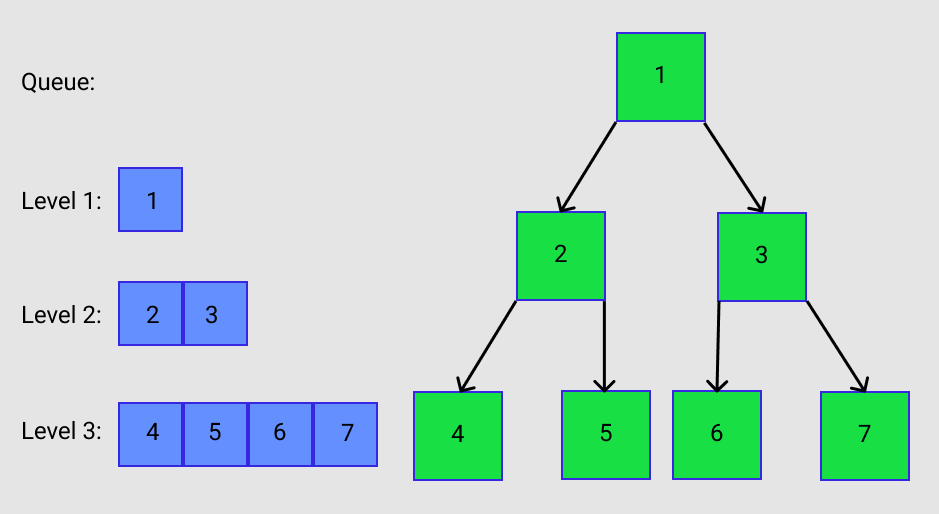
Output:
Level order traversal: [[1], [2, 3], [4, 5, 6, 7]]
Time Complexity
The time complexity for this algorithm is O(N). “N” is the total number of number of nodes in the tree. This is because each node gets traversed once.
Space Complexity
The space complexity for this algorithm is O(N). The result list that is returned contains the total number of nodes (N) that were initially contained in the tree. Also don’t forget that O(N) space is required for the queue. Although the queue at most will contain N / 2 nodes remember that constants are disregarded with Big-O. So O(N/2) is actually just O(N) Similarly, the space complexity of the result list and the space complexity of the queue do not get added together. The final space complexity is O(N).
If you want some more Big-O tips and tricks, then I know of a great place to start.
Get Better at Algorithms!
Algorithms and data structures are pretty tough. They are definitely taking a while for me to get the hang of them. However, there are some great resources out there, and I feel obligated to share some that have been most helpful to me. If I missed any that have been helpful to you, be sure to mention them in them comments.
- Cracking the Coding Interview – Great resource. Really gets you in the right mindset for interviews. Sometimes though, I feel that the style of the coding can be confusing. This repo does a great job of filling in the blanks.
- Grokking the Coding Interview – Can’t emphasize this one enough. Haven’t seen it mentioned it too often. Explains patterns that occur in different coding challenge problems. Great at providing a big-picture of all the different algorithm problems you might encounter. Check it out here.
- Kevin Naughton Jr. – Awesome YouTube channel. Great at going over problems and gives helpful advice.
- Base CS – Vaidehi Joshi does a great job of laying out the fundamentals of algorithms and data structures. Check out the blog series here. She also has a podcast that I give two thumbs up.
- Coding Challenge Website – There are plenty of different ones to choose from. HackerRank, CodeWars, and Edabit all seem to be pretty popular. I personally use LeetCode. Find the one that works for you!
- Pramp – Do mock interviews! The sooner the better! Pramp has been a huge help to me.
Well, I hope that was useful. Thanks for reading my post and best of luck with your learning about data structures and algorithms!