
In the computing world a cache is hardware or software that is used to temporarily store data. Let’s learn more about when a cache is used, how caching works, and the different types of caches.
What is cache?
For starters, let’s make sure that we are pronouncing the word correctly — CASH. Ok now that we have that cleared up, let’s move on to more exciting things.
Oh! One more thing. Perhaps the most important thing that you can take away from this article is this: the main goal of a cache is to shorten data accessibility time.
I promise that I will explain how a cache does this in just a little bit, but first let me use an analogy to illustrate what a cache is. It is going to require your imagination 🙂
Let’s imagine a world where every time we needed to take a shower, we would first have to make a dedicated trip to the supermarket to get all of the soap and shampoo that we need. Also we can only get an amount that would be enough for just one shower. In this make-believe world, there is no such thing as shampoo bottles or bars of soap. Sounds kind of inconvenient huh? 🙁
Luckily we live in a world with shampoo bottles! Shampoo bottles allow us to locally store what we need for our shower needs! We don’t need to make a trip to the store for every shower that we take!
This is caching in a nutshell. A cache is a readily accessible storage media that is used to store frequently accessed data from the main data store. So, in the analogy the shampoo bottle represented a cache. Without caching, a client would need to send the same data requests to the main data store again and again. These requests will take longer because the request has to go all the way to the main data store and then the response has to go all the way back to the client. This is like going to the supermarket to buy shampoo every time you need to take a shower.
Sounds like caching is a much more convenient and cleaner solution 🙂
How cache works
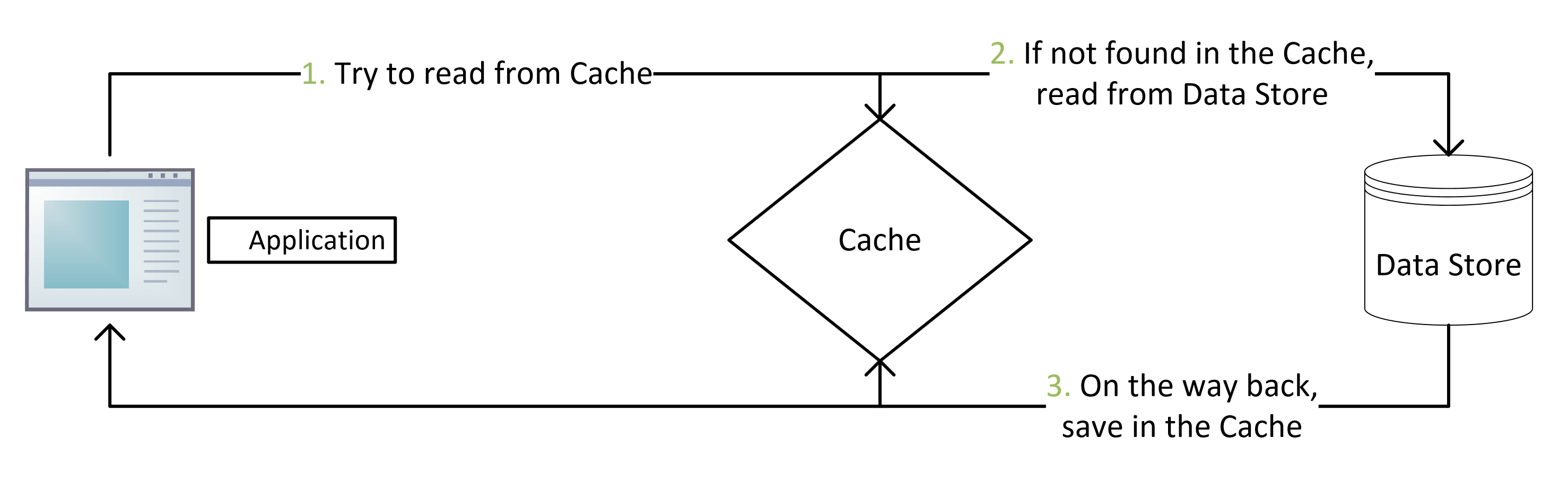
With caching, for every request the client will first check the cache. If the data is in the cache, then this is a cache hit. If the data is not in the cache, then this is a cache miss. The request would then be sent to the main data store and fetched from there. The fetched data would then be copied to the cache for future use. Once the data is stored to the cache it will continue to be delivered from the cache until it expires or is cleared.
Cache invalidation
You might have noticed that the data is being copied from the main data store to the cache. You might ask, “Well, what happens when the data in the server changes? How will the cache know?”. This is where cache invalidation comes in. There are three main schemes that are used: write-through, write-around, and write-back.
Write-through cache
In this scheme data is written into the cache and the main data store at the same time. This scheme allows for complete data consistency between the cache and the storage. It also ensures that no data will get lost in the case of a crash. A drawback to this scheme is that every write operation needs to be done twice which results in higher latency for write operations.
Write-around cache
This scheme has the data written directly to the main data store, but not to the cache. The advantage of this is that the cache won’t have to handle a large amount of write requests that will not be re-read. The disadvantage is that a read request for recently written data will result in a cache miss and the read request would instead be sent to the main data store. This will result in higher latency for read operations.
Write-back cache
With this scheme, the data is written just to the cache. After a specified amount of time the data that is being stored in the cache will then be written to the main data store. This scheme results in low latency and high throughput for write operations. However, if there is a crash then the data will be lost, because the only copy of the data is in the cache.
Types of caches
Cache server
A cache sever is a dedicated server that caches web resources. These caches are used in content delivery networks (CDN) or web proxies. Cache servers are able to be stored in my different geographic locations, so that the client’s request and the data store’s response does not need to travel as far.
Browser cache
Web browsers can store data in their local cache so that the data doesn’t have to be fetched from a server for every request that is sent. This helps to cut down on latency.
Memory cache
Memory cache is a caching mechanism that is actually a part of the computer. The computer is able to take frequently requested data and store certain parts of the data in Static RAM (SRAM). Accessing data from the SRAM is faster than the computer having to access it from the hard drive.
Disk cache
Disk cache is just like memory cache. The only difference with disk cache is that instead of storing memory to the SRAM, it stores it to the RAM.
Cache eviction policies
Cache eviction policies are the instructions for how each cache should be maintained. The list below includes the most frequently used ones, but a more detailed list can be found here.
- Least Frequently Used (LFU): Counts how often an item is needed. Those that are used least often are discarded first.
- Most Recently Used (MRU): Discards the most recently used items first.
- Least Recently Used (LRU): Discards the least recently used items first.
- First In First Out (FIFO): The cache first evicts the block that was accessed first. It doesn’t matter how often or how many times that block was accessed before.
- Last In First Out (LIFO): The cache first evicts the block that was accessed most recently. It doesn’t matter how often or how many times the block was accessed before.